
Manifesto
Building the Future of AI Data
The field of artificial intelligence continues to evolve with increased development of AI applications. Advanced compute infrastructure, open-source Large Language Models (LLMs), model marketplaces, and early examples of AI assistants and autonomous agents are emerging throughout the technology landscape.
The Data Crisis and Our Vision
/CHALLENGE/
Data ScarcityAlthough compute infrastructure is important to democratize AI model training, the pressing issue for AI development is the enormous amount of data needed to pre-train, fine-tune, and enhance LLMs. In fact, AI firms may run out of "high-quality, natural data sources" as early as 2026, and they may run out of lower-quality text and image data "between 2030 and 2060"[1].
Similar to the oil shortage during the early 1900s, due to the mass production of personal automobiles, the proliferation of a multi-modal world, with thousands of open-source proprietary and application-specific AI models, requires new economic structures and applications to incentivize data collection, contribution, and creation at a global scale.
/SOLUTION/
Collaborative Training and Distributed DataOne solution to data scarcity is distributed data collection through collaborative training models. This is an approach where users are incentivized to collect, contribute, and create data for mutual benefit. These models will encourage coordinated and distributed large-scale data collection to generate real-time datasets.
- Reinforcement Learning from Human Feedback (RLHF) is a method that improves AI responses by using human feedback. This involves human feedback on the AI's answers to guide it to produce better responses.
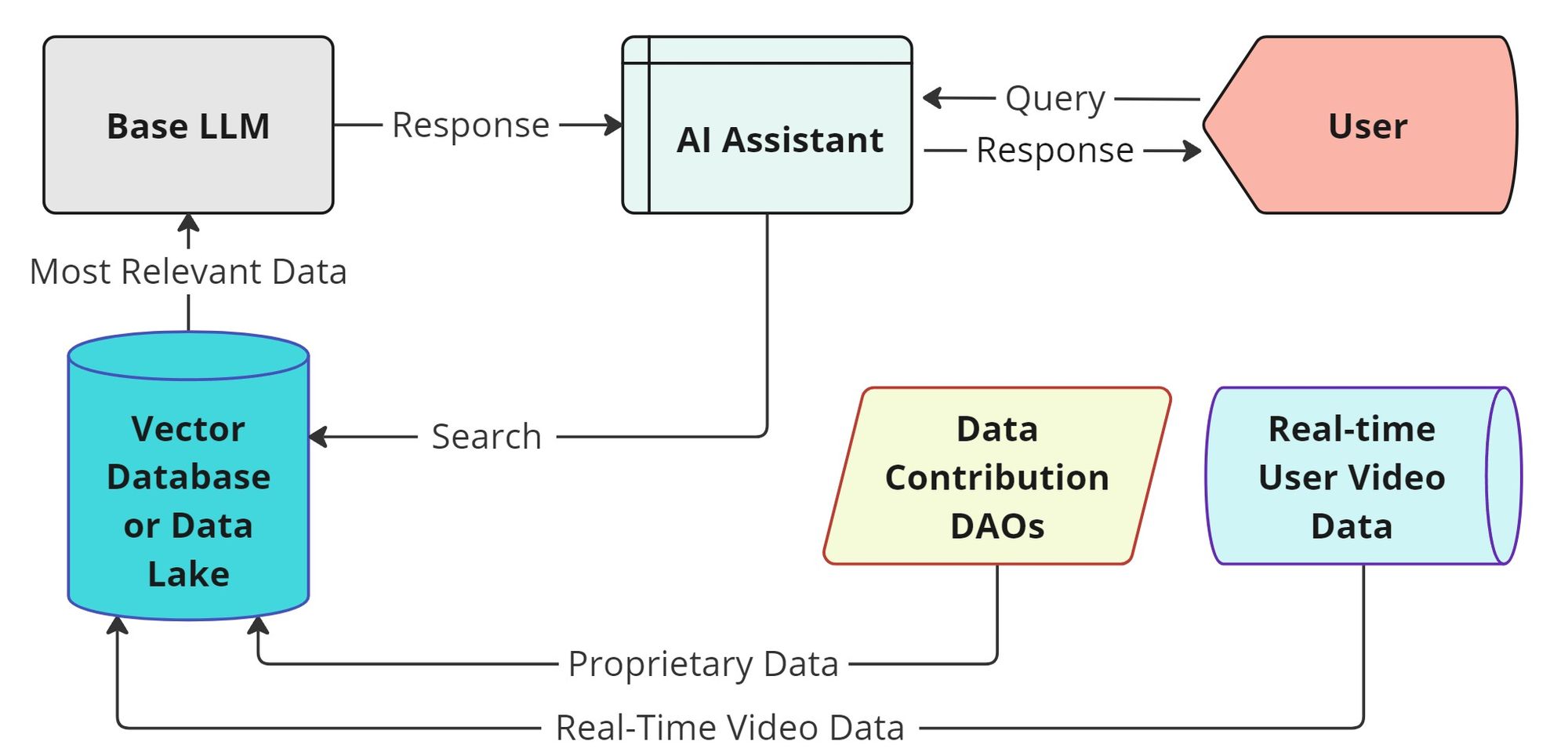
- Retrieval Augmented Generation is a method that combines searching for information with a response creation enhancing responses by fetching relevant content from data sets during response creation.
- Long-Context Models are inherently multimodal, handling diverse data formats like code, text, audio, and video efficiently.
/APPROACH/
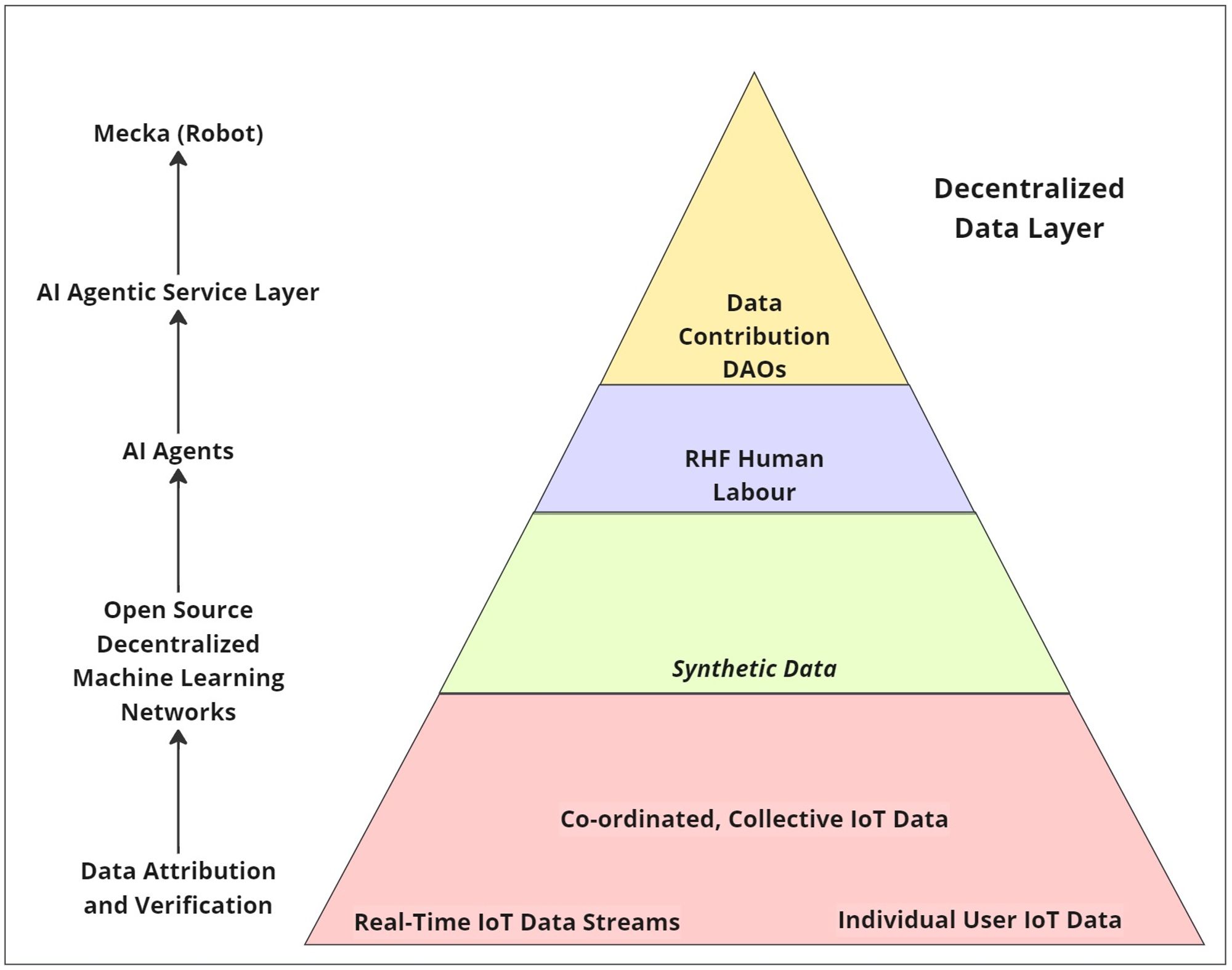
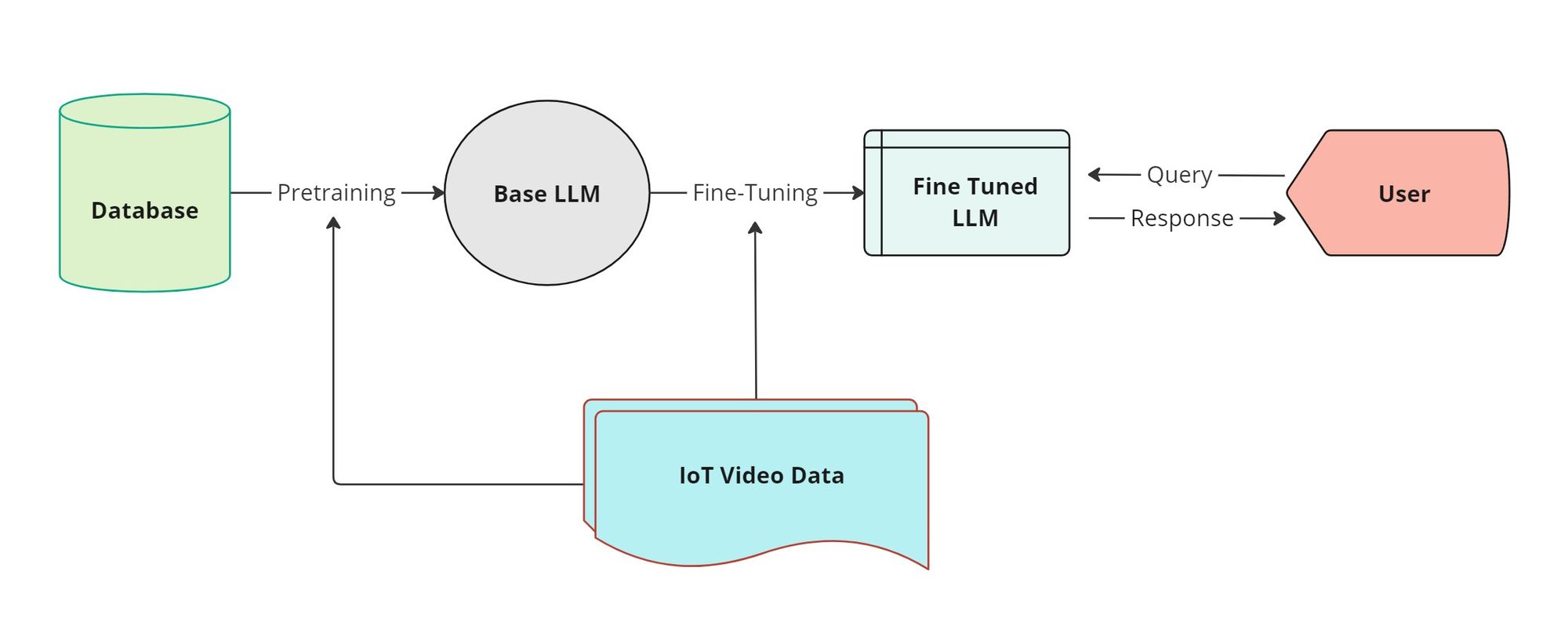
IoT Devices and Data CollectionAdvanced IoT networks enable users to install, monitor, and operate devices to collect data from their physical environment. This data can be used to form large-scale data sets comparable to those collected by central authorities using far fewer resources.
Data collected from IoT devices is granular and allows for precise monitoring, analysis, and decision-making based on specific and real-time information. This data, when applied to LLMs either through RHLF fine-tuning, RAG optimization, or Long context models, will allow for autonomous AI responses to real-time data-enabling a live autonomous service layer that is responsive to real-world events.
/INNOVATION/
Interactive Forms of IoT DataExpanding on automatic methods of IoT data collection, Social-AI applications with collaborative structures offer a new paradigm of coordinated and collective IoT data contribution. Personal IoT (smart technologies) device users can contribute permissioned, personal and real-time data to train highly personalized LLM assistants, avatars, and companions.
Coordinated, collective social IoT data will be gathered through interactive social activities interwoven with the real world. These social activities will be interactive and implicit. They will couple real-life daily tasks with IoT data collection, monitoring human feedback.
/MARKETPLACE/
Distributed RHLF LaborRHLF is considered a "significant advancement in the field of Natural Language Processing (NLP)"[2]. However, scaling RHLF by gathering human reference data is costly as it involves large amounts of human labor.
Distributed marketplaces for RHLF labor can be used to match model builders using open-source model training networks with data contributors who are willing to participate in manual data aggregation labor, data sharing, surveys, events, user feedback, apps, or other routine data acquisition tasks.
/RESEARCH/
Research Groups and DataCollaborative incentives will be used to collect data from specific expert groups, as well as non-expert groups willing to participate in data contribution tasks. Research groups may be incentivized to contribute their proprietary (private and expert) data to open-source inference and model training networks either through RAG model optimization or as context for Long context models.
RAG combines generalized models with an "authoritative knowledge base" to optimize model results, whereas Long context models, such as in Google's Gemini 1.5, accept any data format, code, text, audio and video.
/VISION/
The Multi-Modal FutureAs technology infrastructure expands, collaborative economic structures will incentivize a new data economy. Distributed IoT data collection and proprietary private data contributions will increase exponentially in value and form the foundation for a multi-modal world.
The Personal AI is the realization of the "invisible computer," seamless technology embedded in the user's material and digital sphere through external and wearable IoT devices. This social-technological realization is just the beginning.
As the automobile revolutionized personal mobility worldwide, the development of personal AI models and future Meckas will expand human autonomy across the universe.
© 2025 Carbon Based Technology Corp., operating as Mecka AI.